How To Create Tables In Spark SQL: A Comprehensive Guide - [We Did Not Find Results For: ... ]
Can you truly harness the power of data without mastering the art of table creation and manipulation? Creating and managing tables, especially within the dynamic realm of Spark SQL, is the cornerstone of any successful data-driven initiative.
The world of data is a bustling marketplace of information, and tables are the organized stalls where we display our wares. In the context of Apache Spark, particularly when using Spark SQL, the creation of tables is not merely a technical task; it's an act of crafting the very foundation upon which complex data operations are built. While the syntax of creating tables in Spark SQL shares similarities with standard SQL, the true power lies in leveraging Spark's unique capabilities and constructs.
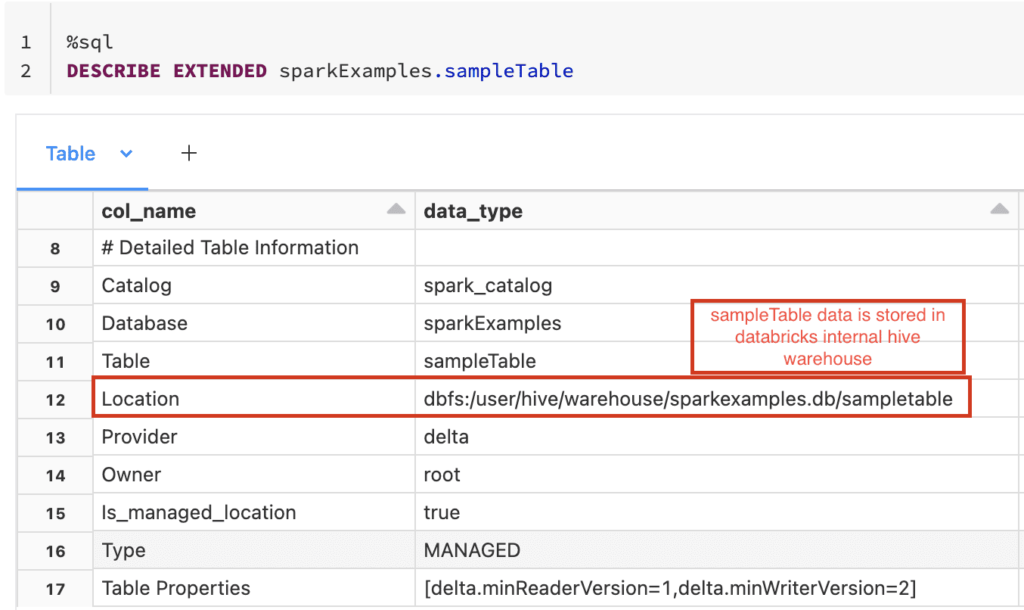
The fundamental structure for creating a table in Spark SQL provides a familiar starting point. However, the nuances come alive when you delve into the specifics of Spark's offerings. One such advantage is the ability to create external tables, which allows you to point your table definition to data already existing in a storage location, such as a data lake or cloud storage. This is in contrast to managed tables, where Spark SQL handles both the data and metadata.
- Ainsley Earhardt Age Birthday More Latest Updates
- Watch Vega Online Streaming Movie Info Latest Updates Alternatives
Consider the use of Iceberg tables, a powerful format for data storage and management within Spark. The primary method for interacting with Iceberg tables is through SQL, combining the strength of Spark SQL with the flexibility of the DataFrame API. You have the ability to create and populate Iceberg tables with data, giving you the versatility to manage structured data effectively.
When you're dealing with Iceberg tables, the path you specify is key. If you provide a path, you're essentially instructing Spark to create an external table from the data stored there. If you do not provide a path, Spark will create a managed table. The choice between external and managed tables will impact how the data and metadata are managed. Furthermore, the source of the data, whether it's 'parquet', 'orc', or another format, dictates how the data is read and written.
In practical scenarios, you might find yourself working with lakehouse tables, which serve as a foundation for data pipelines. You might use these lakehouse tables as the bronze layer, ingesting data from CSV files, and then use those same tables to create views for your warehouse. The process will also allow the construction of tables in a database using Spark. For example, you could create a database via a serverless Apache Spark pool job, and create tables from within Spark.
- Stream Movies Shows Now Find Where To Watch
- Hdhub4u Features Risks Alternatives What You Need To Know
One crucial aspect to consider is the table's data source. If you don't specify the source, Spark will use the default data source configured by `spark.sql.sources.default`. This default dictates how Spark interprets and reads the data.
When creating tables, particularly if you're dealing with data in an ACID-compliant format, like ORC, certain considerations apply. Alterations to such tables may require specific procedures, such as creating a new table with transactional properties, copying data, and renaming the new table.
The commands for creating tables, including `CTAS` (Create Table As Select) and `RTAS` (Replace Table As Select), embrace a wide range of Spark creation clauses, providing you with precise control over your table's structure and behavior.
There is also the ability to create a temporary view within Spark. When using `CreateOrReplaceTempView`, tables are created in the `global_temp` database. When you want to create a table and populate it with data from a temporary table, modifying the query to `CREATE TABLE mytable AS SELECT FROM global_temp.my_temp_table` will achieve this goal.
Remember that if you're managing Delta Lake tables, the table configuration is often inherited from the storage location where your data resides. Therefore, any `TBLPROPERTIES`, `TABLE_SPECIFICATION`, or `PARTITIONED BY` clauses should match the Delta Lake specifications.
Here is a table of basic commands used for creating tables in spark:
| Command | Description | Example |
|---|---|---|
| CREATE TABLE | Creates a new table with specified schema and properties. | `CREATE TABLE my_table (id INT, name STRING) USING PARQUET;` |
| CREATE TABLE AS SELECT (CTAS) | Creates a new table and populates it with data from a SELECT query. | `CREATE TABLE my_table AS SELECT id, name FROM another_table;` |
| CREATE OR REPLACE TABLE | Creates a new table if it doesn't exist, or replaces an existing one. | `CREATE OR REPLACE TABLE my_table (id INT, name STRING) USING DELTA;` |
| DROP TABLE | Deletes an existing table. | `DROP TABLE IF EXISTS my_table;` |
| ALTER TABLE | Modifies the structure or properties of an existing table. | `ALTER TABLE my_table ADD COLUMNS (age INT);` |
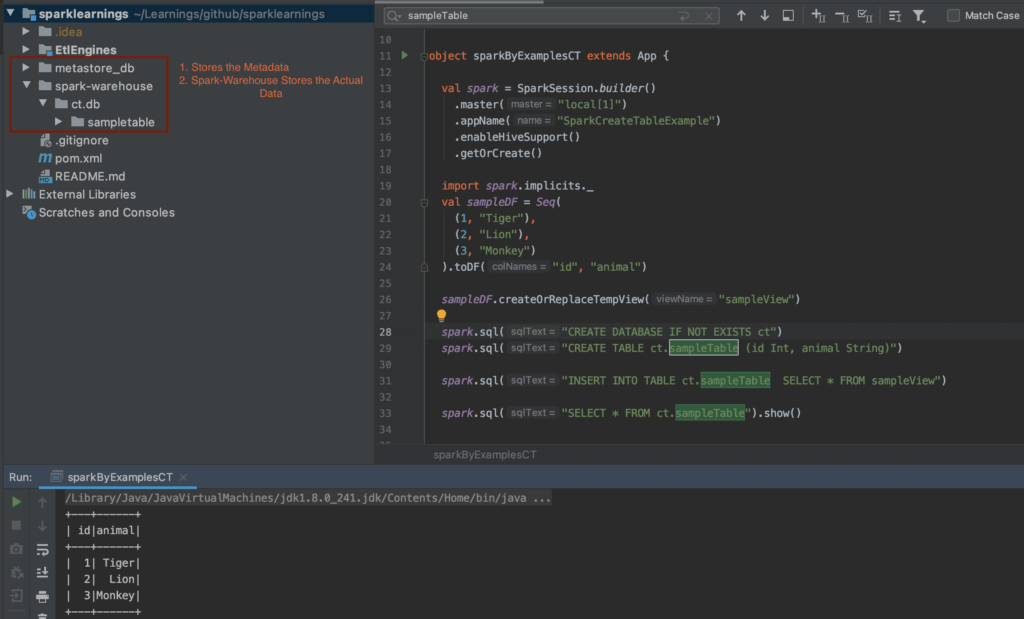
Here is a basic example of how you can create a simple managed table using Spark:
from pyspark.sql import SparkSession# Create a SparkSessionspark = SparkSession.builder.appName("ManagedTables").getOrCreate()# Define the schema for the tableschema ="id INT, name STRING, city STRING"# Create the managed table with the specified schemaspark.sql(f"CREATE TABLE IF NOT EXISTS my_managed_table ({schema})")# Insert some data into the tabledata = [(1, "Alice", "New York"), (2, "Bob", "London")]df = spark.createDataFrame(data, schema.split(","))df.write.mode("append").saveAsTable("my_managed_table")# Query the table to verify it's been created and populatedspark.sql("SELECTFROM my_managed_table").show()# Drop the table when you're finishedspark.sql("DROP TABLE IF EXISTS my_managed_table")
This example illustrates the core concepts of managed table creation, including defining the schema, creating the table, inserting data, querying the table, and finally, dropping the table. By using the proper commands, you can efficiently create and manipulate tables within your Spark environment.
When working with Hive tables, you will encounter the distinction between internal and external tables. An internal table, is a Spark SQL table that manages both the data and the metadata. The difference between internal and external tables lies in how the data and metadata are handled.External tables, on the other hand, point to data in a specific external location, and you, the user, is responsible for managing that underlying data.

Detail Author:
- Name : Logan Dietrich
- Username : solon65
- Email : elwin98@ebert.com
- Birthdate : 1992-10-08
- Address : 521 Mary Hollow Townechester, KS 83460-7998
- Phone : +1-715-704-7999
- Company : Swift, Effertz and Huel
- Job : Mathematical Science Teacher
- Bio : Laborum sed iusto omnis totam nostrum mollitia ea. Eius non earum quam officiis unde ut ad. Perspiciatis dolorem aut earum.
Socials
tiktok:
- url : https://tiktok.com/@gerson.dicki
- username : gerson.dicki
- bio : Doloremque quaerat ad voluptas dolor nihil rem neque cumque.
- followers : 1195
- following : 1379
twitter:
- url : https://twitter.com/gerson_dicki
- username : gerson_dicki
- bio : Dolores a ut hic voluptatum voluptas quis libero. Placeat qui a illo aut quia. Exercitationem molestias est voluptas et.
- followers : 4654
- following : 730
instagram:
- url : https://instagram.com/gerson_dicki
- username : gerson_dicki
- bio : Sapiente nesciunt error earum dicta id et reprehenderit id. Sed qui quo voluptas nam.
- followers : 4408
- following : 1254

{kind=link}